This post is the first of a two parts series of articles about how to tune Akka configurations
- Part-1: Initial Akka Configurations
- Part-2: Gather and analyze Akka metrics with Kamon and stackable traits
At some point, whether it is during your new actor-based system planning, or after you have a prototype working, you’ll probably find yourself digging into the Akka Docs to find the right combination of possibilities for routing, dispatcher, number of actors instances and so forth… Depending on the complexity of your system and performance requirements, this could get tedious.
Part-1: Initial Akka Configurations
Let’s start with Akka configuration, specifically the configuration of actor-instances, routing strategy and dispatchers & executors. Below is the relevant section of the application.conf
{
akka {
actor {
akka.actor.deployment {
/my-service {
nr-of-instances = ???
router = ???
dispatcher = "my-dispatcher"
}
my-dispatcher {
executor = ???
type = ???
}
The number of actor instances
I like to start by thinking about how many instances of an actor are suitable?
akka.actor.deployment {
/my-service {
nr-of-instances = ???
}
}
The size may depend on other configurations like routing strategy, dispatcher, threadpool size and more. Nevertheless, the nr-of-actor ‘strategy’ can already be decided at this point. Let’s review our options and use cases:
Single instance (or- Domain actor)
- A dedicated actor for low-priority side-effects like sending metrics, write to a log or to a cache and so forth.
- A mutable, single-source that needs to be handled(Cache)
- When you need to work sequentially for whatever reason
Fixed number of instances
- Instance per a copy of resource, or per a mutable resource
- For sharding, i.e. when you manage a distributed key-value cache and want to shard the inputs, then you may want an actor to manage each shard
- To execute tasks in parallel, and you don’t think you’ll need to manage Back-Pressure nor to scale up
Resizeable number of instances(when using a router)
akka.actor.deployment {
/parent/router {
resizer {
lower-bound = ???
upper-bound = ???
pressure-threshold = ???
messages-per-resize = ???
...
}
}
}
It is possible to configure resizable routees (actor instances managed by a router).
Routees can be added or removed dynamically, based on performance. You can configure specifically how much to scale up and down in case of unusual behavior.
Scale / Back-Pressure DIY!
When one component is struggling to keep-up, the entire system needs to respond in a sensible way.
You’re might be somewhat familiar wit Akka-Streams, widely known as a framework that manages your back-pressure. It’s possible to imitate the general behavior by yourself.
Let’s review some scenarios in which you may want to scale your routees:
The producer(In our use case, one of your actors), can produce faster than the received consumer(actor or any other source) can handle.
 In this case you may:
In this case you may:
-
Back-pressure the producer, i.e. reduce the number of producer’s routees.
-
Add more consumers(routees…)!
-
Leave it. You don’t necessarily need to back-pressure. It may lead to a loss of messages (bounded mailbox) or running out of memory…

The consumer is faster than the producer.
Here the consumer will block waiting for the next item.
-
Remove some consumers(routees…)!
-
Add more producers if your system can theoretically produce faster.
-
Leave it. Then you may not get the most from your machine.
Actor per-request
 “You press, you make a request, the Meeseeks fulfills the request, and then it stops existing”(Rick Sanchez)
“You press, you make a request, the Meeseeks fulfills the request, and then it stops existing”(Rick Sanchez)
Actor per request works very similarly. An instance is created for every request, process it and then it will be destroyed.
You can configure Spray/Akka-HTTP to work in actor-per-request mode or do it yourself. However, it is not part of the Akka configuration, so I won’t go into too much detail. In a nutshell:
-
Easy to manage state in the actor, because the context is always of a specific request, hence you don’t have to maintain any mapping of State => Request
Note that there is a context-switches overhead which could theoretically lead to memory issues
Routing
Akka provides “strategies” for the Akka router to define the workload distribution among actors.
akka.actor.deployment {
/my-service {
router = ???
}
}
Strategies Overview
Let’s quickly review the the routing strategies
-
Random - Distributes messages randomly
-
Round-Robin - Distributes messages in sequence
-
Smallest-Mailbox - Sends the message to the smallest mailbox
-
Broadcast - Distributes every message to all routees.
-
Scatter-Gather-First - Distributes every message to all routees. Only the first to respond will execute the task.
-
Tail-Chopping - Sends the message to one, randomly picked, routee and then after a small delay to a second routee.
-
Consistent-hashing - Uses consistent hashing to select a routee based on the sent message
-
In-Code - Custom your own routing by routing it yourself
Strategies Cheatsheet
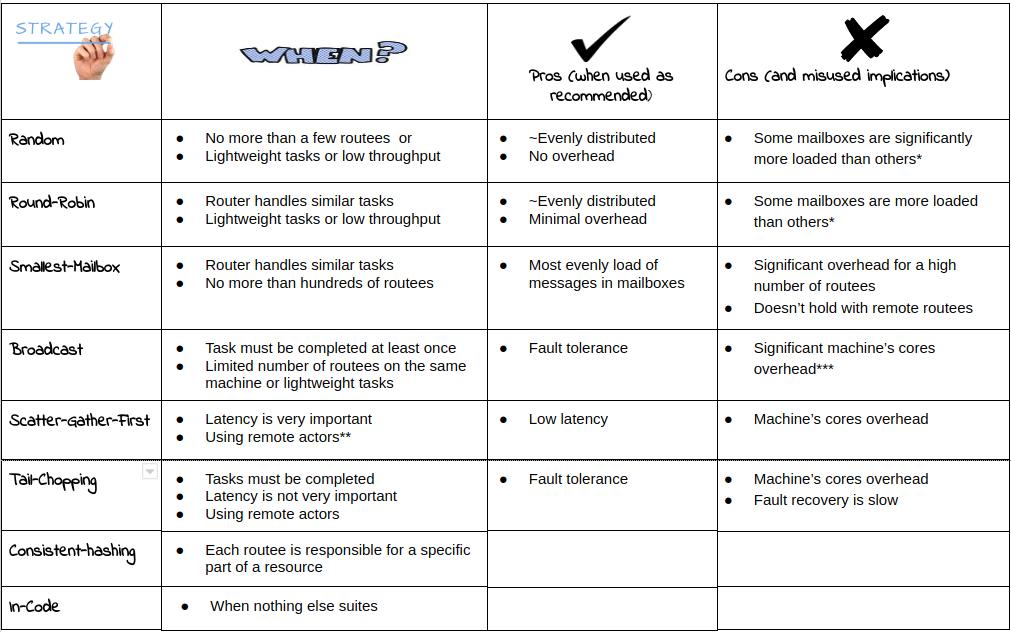
*Can be solved by increasing the number of routees (which may cost in context-switches overhead)
**As a replacement for ‘smallest mailbox’. Latency differences could be high among connections to remote actors)
***The overhead depends on the task, whether it on the same machine or not
Dispatchers and Executors
akka.actor.deployment {
/my-service {
dispatcher = ???
type = ???
}
}
Dispatchers are what makes Akka actors “tick”, means put messages in mailboxes and route them. In addition, they are also an implementation of ExecutionContext, means they can execute Runnables and so a Scala Future.
my-dispatcher {
executor = ???
throughput = ???
....
}
Fork-Join-executor
my-dispatcher {
executor = "fork-join-executor"
....
}
Java 7 introduced the Fork-Join executor.
As the name suggests, it forks a task into subtasks, each executed by a different thread, and joined the results.
There are two main characters that are worth mentioning here. According to Oracle docs -
-
“It is designed for work that can be broken into smaller pieces recursively”.
Hence it is best for recursive problems - where a task can be broken into sub-tasks such that they would be executed in parallel and their results would be collected.
-
“The fork/join framework is distinct because it uses a work-stealing algorithm. Worker threads that run out of things to do can steal tasks from other threads that are still busy”
Fork-Join shows better performance in most cases, compared to old Thread-Pool-Executor. It makes a better use of resources, since the idle threads can steal tasks from busier threads. However, there is a built-in danger here.
Regarding the first statement, when a ‘Fork’ is performed, we have multiple threads and each of them is responsible for running a task. From the second, when a thread is finished it can take another task. But what if he got stuck performing this task? The other threads will wait on the ‘Join’ at some point, which is a threads starvation.
my-dispatcher {
executor = "fork-join-executor"
fork-join-executor {
# Min number of threads to cap factor-based parallelism number to
# Note that these threads will be created anyway on fork'
# so try to avoid an unnecessary overhead.
parallelism-min = ???
# Parallelism (threads) ... ceil(available processors * factor)
parallelism-factor = ???
# This is NOT an upper bound on the total number of threads!
# Max number of threads to cap factor-based parallelism number to
parallelism-max = ???
....
}
}
A common case is to use Fork-Join executor for future tasks inside an actor. Here, the dispatcher’s configuration of the actor should be considered as well. For example, the more threads you have for the actor, the more ‘future’ tasks will be performed, and you may want more threads for them.
Thread-pool-executor
The old Java 5 executor for asynchronous task execution can still fit in some cases and without the Fork-Join overhead.
While Fork-Join breaks the task for you, if you know how to break the task yourself then your code should be already built as a minimal task, executed by a single thread, which fits a thread-pool-executor.
The thread-pool executor is used by Akka Dispatcher and PinnedDispatcher.
Dispatcher allows you to define ‘min’, ‘max’ and increase ‘factor’ / ‘fixed’ size for your thread pool.
my-dispatcher {
type = Dispatcher
executor = "thread-pool-executor"
thread-pool-executor {
# Min number of threads to cap factor-based parallelism number to
parallelism-min = ???
# Parallelism (threads) ... ceil(available processors * factor)
parallelism-factor = ???
# Max number of threads to cap factor-based parallelism number to
parallelism-max = ???
}
....
}
The key is to find the right balance for actor instances to work in parallel and use the threads as much as they are need so other actors and processes can work as well. It’s also true for the Fork-Join executor and needs to be quite accurate.
PinnedDispatcher dedicates a unique thread to each actor. This is usually not the pattern you want for the machine, given the limited resources. Hence, it makes sense for the actor to share a pool of threads. However, if your actor performs a preferred task, you won’t want its instances to share the pool.
Do not use it if you have more instances than the number of cores in the machine. It is also not recommended for Futures, because you’ll probably need more than 1 thread…
Affinity-pool-executor
my-dispatcher {
executor = "affinity-pool-executor"
....
}
This executor tries its best to have your actor instance always schedule with the same thread, which should increase throughput.
This is recommended for a small number of actor instances, where you have much more instances than threads, it is just not possible.
Tips

-
Don’t use the Akka default dispatcher for your actorSystem, or for the actors themselves. Note that external Akka based frameworks use it as default, and you should configure a dedicated dispatcher for them as well.
-
Have a different dispatcher for each actor, and for Futures inside an actor.
-
Dispatchers have a ‘throughput’ parameter, which “defines the maximum number of messages to be processed per actor before the thread jumps to the next actor” Setting It to a higher value than the default, 1, is likely to improve performance so long as it is not part of the Affinity-pool dispatcher, and your actors are generally not very busy (otherwise the lack of fairness can cause a high load in some mailboxes).
-
Read this terrific post in the ScalaC blog. It explains dispatcher’s internals in details.
Next
In Part-2 I will show how we monitor and analyze our actor-based system.